如何设计Crawler(三)分布式爬虫设计
我们已经讲了如何设计实现爬虫,如果一台机器又要负责爬取页面又要负责任务的分发很容易成为瓶颈,那么能不能做成分布式的呢?今天就来讲讲如何将爬虫放在多个机器上。
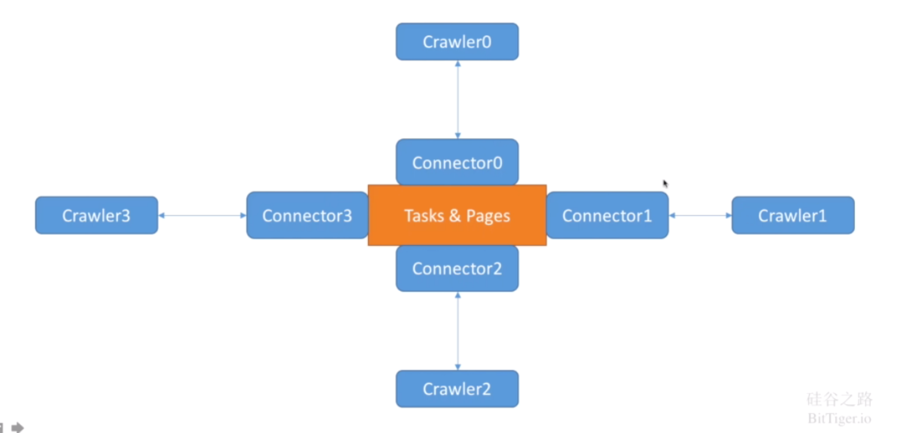
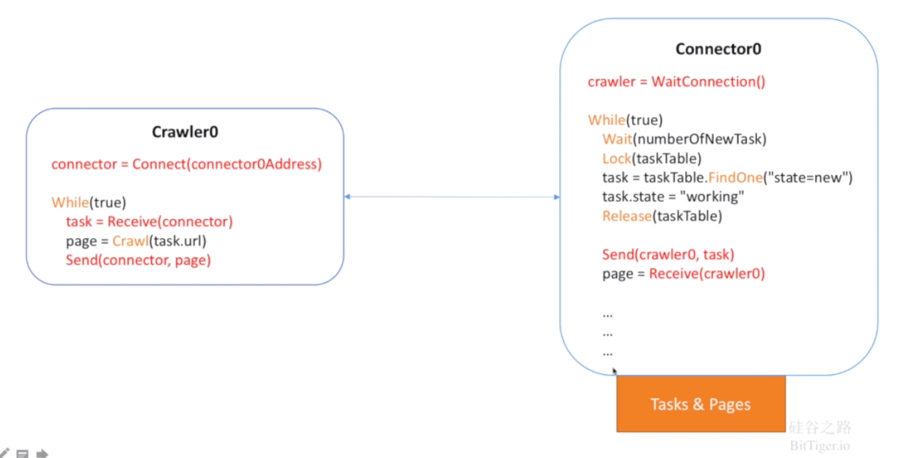
最经典的架构就是Task&Pages在中心,Crawler分布在四周,每个Crawler和一个Connector相对应。
 {width="6.0in" height="2.8848075240594926in"}
{width="6.0in" height="2.8848075240594926in"}
 {width="6.0in" height="3.0521325459317583in"}
{width="6.0in" height="3.0521325459317583in"}
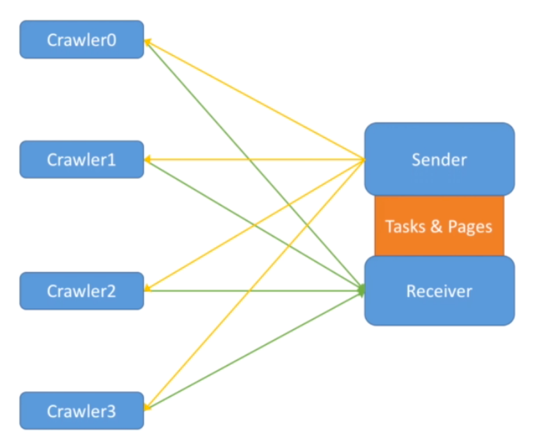
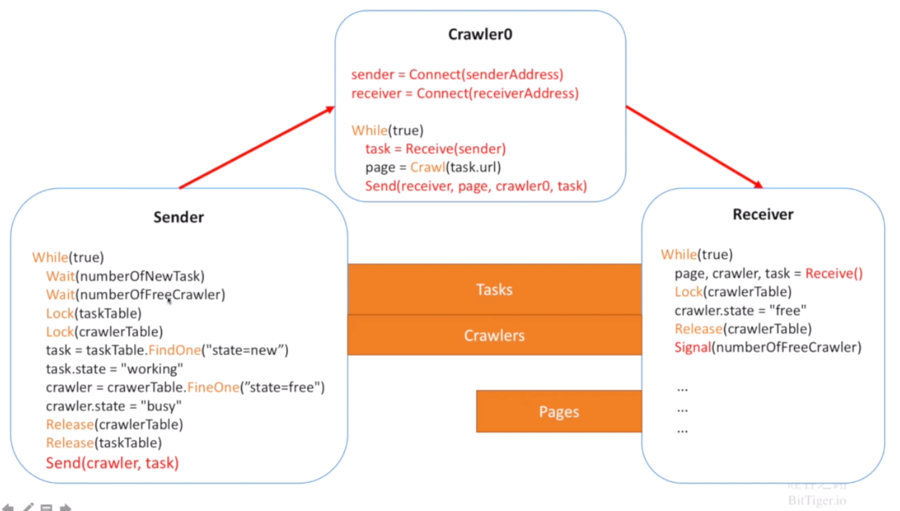
这个架构好像Connector太多了,我们真的需要这么多Connector吗?我们可以实现一个一对多的架构,由统一的Sender给Crawler发任务,统一的Receiver接收结果。这个架构其实并没有减少Crawler和中心的连接数,可是这种架构方便统一管理,免去了协调过多Connector的麻烦,也符合当下微架构的设计模式。
 {width="3.6216655730533684in"
height="2.9818471128608923in"}
{width="3.6216655730533684in"
height="2.9818471128608923in"}
 {width="6.0in" height="3.409429133858268in"}
{width="6.0in" height="3.409429133858268in"}
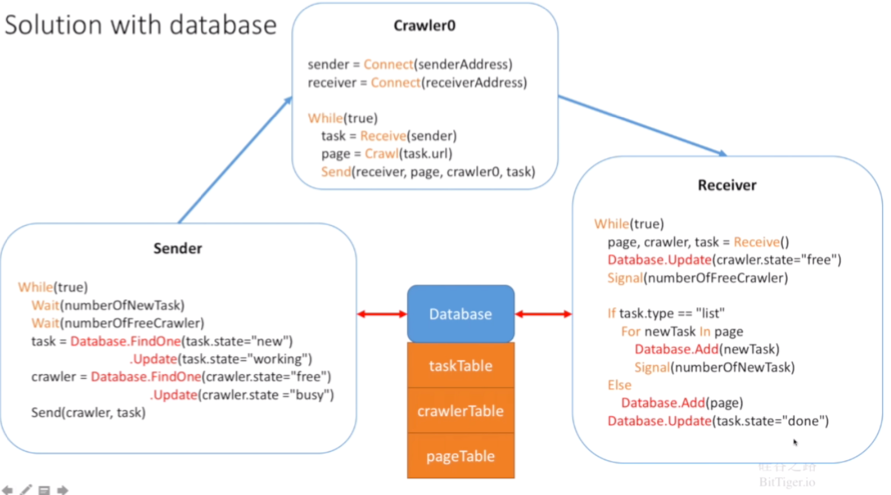
但是总是要锁来锁去有点麻烦,能不能避开锁的问题呢?我们可以利用数据库来解决,直接从数据库里获取数据存放数据数据,让数据库来解决同步机制。
 {width="5.943125546806649in"
height="3.302561242344707in"}
{width="5.943125546806649in"
height="3.302561242344707in"}