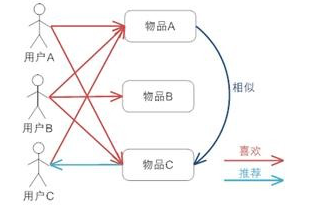
什么是推荐引擎
我们可以将推荐引擎看作黑盒,它接受的输入是推荐的数据源,推荐引擎根据不同的推荐机制可能用到数据源中的一部分,然后根据这些数据,分析出一定的规则或者直接对用户对其他物品的喜好进行预测计算。这样推荐引擎可以在用户进入的时候给他推荐他可能感兴趣的物品。
推荐引擎的分类
在算法模型上大体可以分基于内容的推荐、基于协同过滤的推荐。
基于内容推荐: 即通过内容本身的属性,然后计算内容的相似性,找到与某物品属性相似的物品。
协同过滤:即不依赖于物品本身的物品属性,而是通过其他相关特征,例如人参与的行为数据,来达到推荐物品的目的。 关于协同过滤,又分为以下几个类别:
- 基于物品的协同,即ItemCF;
- 基于用于的协同,即UserCF;
- 基于模型的协同,即ModelCF。
其中,基于模型的协同又可以分为以下几种类型:
- 基于距离的协同过滤;
- 基于矩阵分解的协同过滤,即Latent Factor Model(SVD);
- 基于图模型协同,即Graph,也叫社会网络图模型。
基于内容的推荐原理
基于内容的推荐是在推荐引擎出现之初应用最为广泛的推荐机制,它的核心思想是根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。
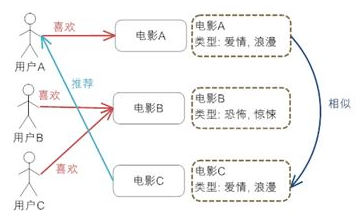
上图中给出了基于内容推荐的一个典型的例子,电影推荐系统,首先我们需要对电影的元数据有一个建模,这里只简单的描述了一下电影的类型;然后通过电影的元数据发现电影间的相似度,因为类型都是“爱情,浪漫”电影 A 和 C 被认为是相似的电影(当然,只根据类型是不够的,要得到更好的推荐,我们还可以考虑电影的导演,演员等等);最后实现推荐,对于用户 A,他喜欢看电影 A,那么系统就可以给他推荐类似的电影 C。
基于用户的协同过滤推荐机制的基本原理
基于用户的协同过滤推荐的基本原理是,根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K- 邻居”的算法;然后,基于这 K 个邻居的历史偏好信息,为当前用户进行推荐。下图给出了原理图.
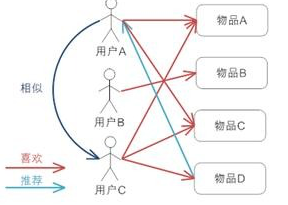
上图示意出基于用户的协同过滤推荐机制的基本原理,假设用户 A 喜欢物品 A,物品 C,用户 B 喜欢物品 B,用户 C 喜欢物品 A ,物品 C 和物品 D;从这些用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似的,同时用户 C 还喜欢物品 D,那么我们可以推断用户 A 可能也喜欢物品 D,因此可以将物品 D 推荐给用户 A。
基于项目的协同过滤推荐机制的基本原理